How to Backup to Amazon S3 [3 Methods]
By Owin Updated on June 26, 2026
Amazon S3, as an object storage service provided by Amazon Web Services (AWS), has become a premium choice for many users' data backup due to its powerful features and excellent cost-performance ratio. This article will detail the specific steps and precautions for backing up data to Amazon S3, helping you successfully complete the backup to Amazon S3 process.

How to back up to Amazon S3
Amazon S3 allows you to backup almost any kind of data, such as synology backup to Amazon S3, backup SQL Server to Amazon S3, etc. Here are 3 methods for you to choose from, so you can make the right choice for your situation.
Method 1. Back up data to Amazon S3 using AWS Backup
1. To backup a temporary file, create a new S3 bucket or use an existing one. There is a file called S3_temp_file.txt in the S3 bucket S3-aws-backup-demo.
Note: Versioning ought to be enabled in the bucket you're planning to backup.
2. Navigate to AWS Backup from your AWS console and go to Dashboard.
3. You can create an on-demand backup or a backup plan on the dashboard. Select Create an on-demand backup.
4. Select S3 under resource type.
5. You have the option to select all buckets or a specific bucket under the bucket name.
6. Check the box that says "Create backup now". This will immediately begin the backup. If you don't want to back up immediately, choose another time.
7. Choose an appropriate option from Retention period dropdown menu.
8. Choose Backup vault to encrypt objects with S3. You can choose one from the list or make your own. Click Create new Backup vault, enter the Backup vault name, and the encryption key.
9. You can choose any existing role that has the necessary rights to backup and restore S3 buckets under the IAM role option. You can alternatively choose Default role, which will generate a new role for you with the appropriate rights.
10. Enter the Key and Value and click on Add tag to add some tags to the backup.
11. Click on Create an on-demand backup.
12. Depending on the size of the buckets you're backing up, the task will take some time. While AWS is backing up the chosen buckets, the status will read "running". The job status will change to Finished after the backup is finished.
13. To view the backup point you created, go to the Protected resources. The S3 files may be restored at any moment up until the designated retention period using this backup point.
Method 2. Back up data to Amazon S3 using AWS CLI
The AWS Command Line Interface (CLI) provides a set of commands for interacting with AWS services, including S3. You can use the CLI to upload files and directories to S3, download them, and manage S3 objects and buckets.
At first, you should create an AWS IAM user account, then you can use this user account to securely access AWS services using the AWS CLI.
✥ Prerequisite: Install and configure the AWS CLI
Now you need to install the AWS CLI to perform backup to Amazon S3 Windows. Below are full instructions based on Windows system.
1. Download and run the Windows installer (64-bit, 32-bit).
Note: Users of Windows Server 2008 v6.0.6002 will need to use a different install method, listed in the AWS Command Line Interface User Guide.
2. Press the Windows Key + r to open the run box and enter cmd and click OK.
3. Enter the command aws configure. Then enter the following when prompted:
AWS Access Key ID [None]: the Access Key Id from the credentials.csv file
AWS Secret Access Key [None]: the Secret Access Key from the credentials.csv file
Default region name [None]: us-east-1
Default output format [None]: json
✥ Using the AWS CLI with Amazon S3
1. If you currently have a bucket created that you want to use, creating another one is not necessary. To make a new bucket named my-first-backup-bucket type, enter the following:
aws s3 mb s3://my-first-backup-bucket
Note: Due to several limitations on bucket naming, such as the requirement that bucket names be globally unique (i.e., no two AWS users may have the same bucket name), attempting the command above will result in a BucketAlreadyExists error.
2. The following command would be used to upload the file my first backup.bak from the local directory (C:users) to the S3 bucket my-first-backup-bucket:
aws s3 cp “C:\users\my first backup.bak” s3://my-first-backup-bucket/
3. By reversing the order of the commands, you may download my-first-backup.bak from S3 to the local directory as follows:
aws s3 cp s3://my-first-backup-bucket/my-first-backup.bak ./
4. Use the following command to remove my-first-backup.bak from your my-first-backup-bucket bucket:
aws s3 rm s3://my-first-backup-bucket/my-first-backup.bak
Method 3. Safe way to backup data to Amazon S3
Utilizing the official tools to backup data to Amazon S3 is sort of complicated. Here we would like to recommend an easier and professional backup software - AOMEI Cyber Backup. It helps users to create enterprise backups (such as VMware, Hyper-V virtual machines, Windows PCs and Server, MS SQL) and archive to Amazon S3 storage.
It uses an easy-to-use web console for centralized backup and management. Even non-tech people can easily backup and archive data with a few clicks. Moreover, AOMEI Cyber Backup facilitates more useful features, like incremental backup, automatically cleanup outdated backup versions.
Now you can click the download button to install this software, and we will guide you on how to use this tool.
Step 1. Click "Source Device". Choose a device type according to the data type that needs to be backed up. Here we choose VMware ESXi for demonstration. Here input the VMware information to bind it.
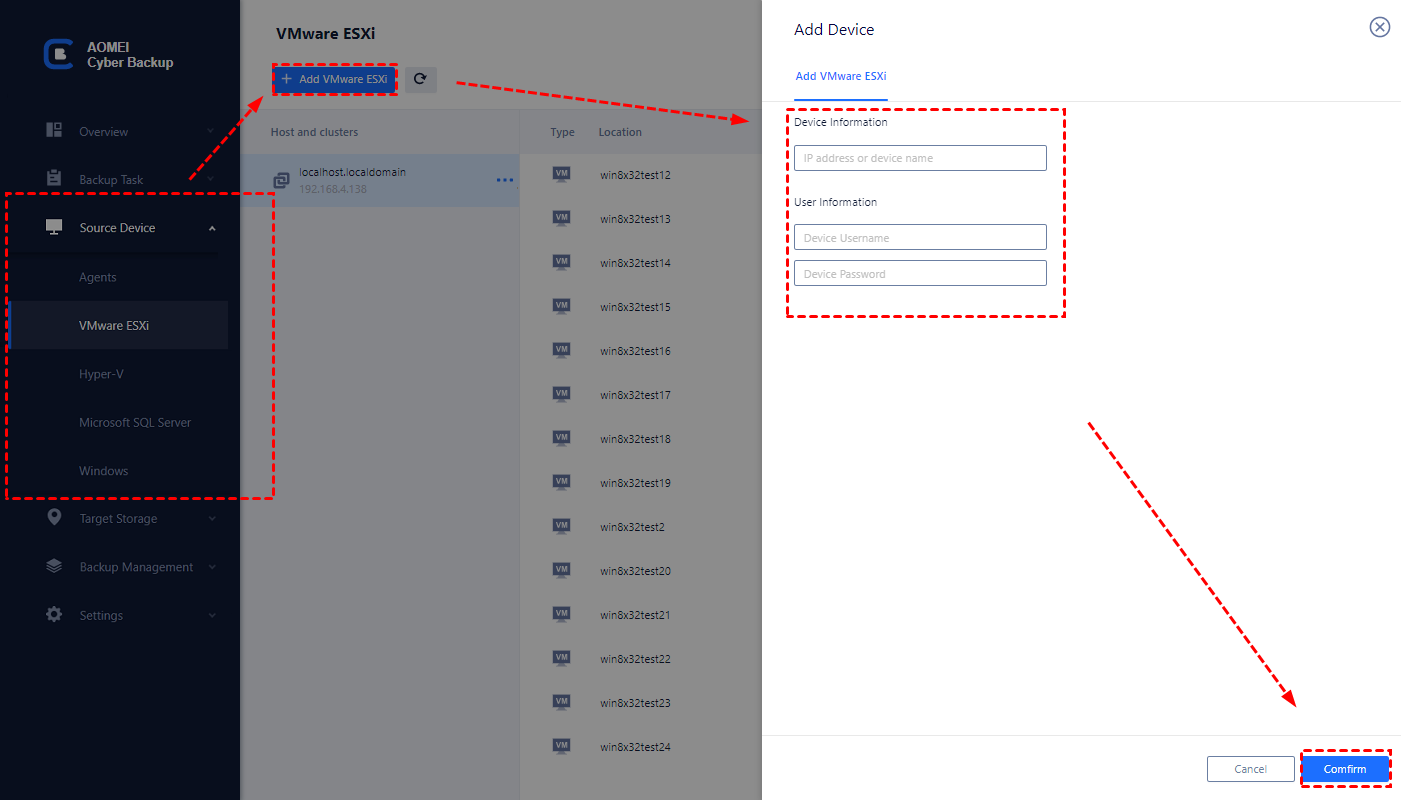
Step 2. Choose a backup type. Here we choose VMware ESXi backup.
Step 3. Configure Task Name, Target Schedule, and other settings according to your needs. To archive the backups to Amazon, check "Archiving backup versions to Amazon S3".
Step 4. Then click Select+. Then input region, username, password, and Bucket to add and select. Then click Confirm.
Step 5. Click the Start Backup button to commit and run the backup task. After the backup is complete, your backups will be archived to Amazon S3 automatically.
Precautions during the AWS S3 backup process
(1) Data Security and Encryption
For sensitive data, it is recommended to encrypt it before uploading.AWS offers various encryption options, such as server-side encryption (SSE) and client-side encryption.
(2) Network and Transmission Costs
Try to choose times when network bandwidth is sufficient and costs are lower for backups, or use batch and incremental backups to reduce data transmission volume and lower transmission costs. At the same time, pay attention to the differences in data transmission costs between different regions and plan the bucket's regional location accordingly.
(3) Storage Strategies and Management
For cold data that is not frequently accessed, you can choose a lower-cost storage tier; for hot data that needs to be accessed frequently, choose a higher-performance storage tier. Regularly clean up unnecessary data in the storage buckets to optimize storage space and reduce storage costs.
Conclusion
Backing up data is vital to protect against data loss and ensure business continuity. Amazon S3 offers a reliable and scalable solution for data backup in the cloud. By following the steps outlined in this guide, you can securely back up your data to Amazon S3 and take advantage of its durability, availability, and cost-effectiveness.
Please remember to monitor your S3 costs and consider implementing versioning or lifecycle policies to optimize your backup to amazon S3 Windows.
